This site is intentionally not blank.
About me


Detail-oriented developer with 3+ years of experience
creating software. Skilled in Python,
TS/JS, Nim, and
SQL with a strong background in
automation and developer tooling.
Proven proficiency in Git and
CI/CD pipelines using GitHub Actions.
Maintains a high standard of communication and
collaboration. Dedicated to continuous learning and
growth. Likes documentation, testing,
and making useful things.
Projects
box2d.nim
- Nim bindings for Box2D, a popular game physics engine.
Nim is a statically typed compiled systems language with C
interoperability. In the sphere of game development in Nim, developers
often have to roll their own physics engine if their game requires
physics. This presents a great opportunity to learn but can be a
daunting task if the developer isn't already familiar with the
underlying math.
This binding solved a personal need to create a physics-based game in
Nim and by creating complete
documentation
and
testing
I was able to effectively solve this problem for others.
 Click to play demo
Click to play demo
wiki data dump
- API for traversing and downloading from Wikimedia Data
Dumps.
Wikimedia uploads routine data dumps from their projects (Wikipedia,
Wikibooks, Wiktionary, etc.), and these are accessible by their
data downloads site. To
query for assets on this site, people often resort to webscraping
which provides a short term solution but can be taxing for Wikimedia's
servers and is prone to failure.
To solve this issue, I created an API that accesses
the index of the site and wraps common query operations around
idiomatic Python classes.
Below is a typical usage of the library.
from wiki_data_dump import WikiDump, File
import re
from typing import List
wiki = WikiDump()
xml_stubs_dump_job = wiki["enwiki", "xmlstubsdump"]
stub_history_files: List[File] = xml_stubs_dump_job.get_files(
re.compile(r"stub-meta-history[0-9]+\.xml\.gz$")
)
for file in stub_history_files:
wiki.download(file).join()
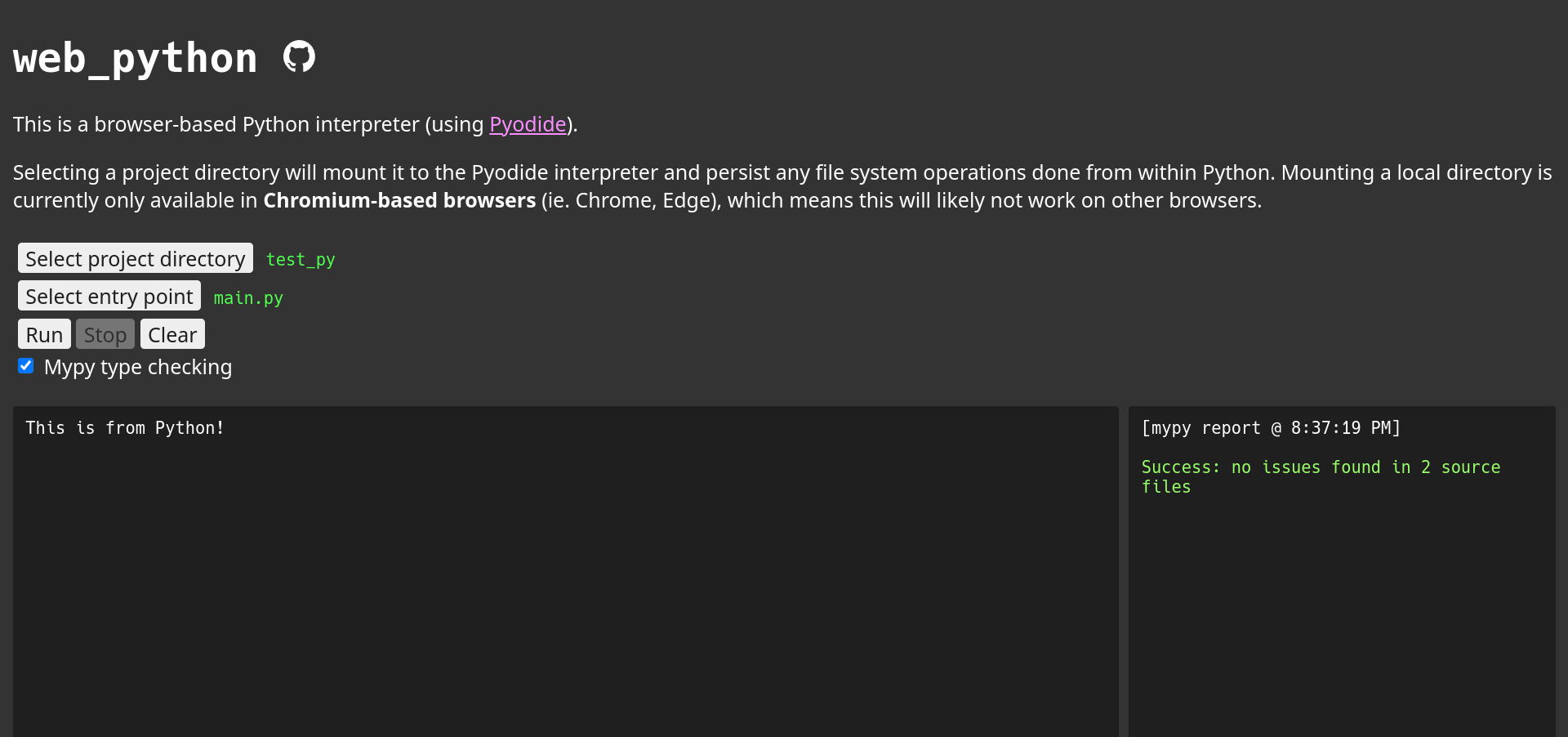
web python
- Online interpreter for Python with optional static type
checking.
Online Python interpreters usually don't have operability with the
user's actual file system, and you have to upload individual scripts
and files to use them within the interpreter, which can be tedious. In
addition to this, the code is often run within a cloud service (such
as
Google Colab) which
may not always be desired.
Pyodide is a WASM-based Python interpreter and when provided a native
file system directory handle as a virtual file system mount point you
can use the interpreter very much like a
native Python installation: file reads/writes are updated in
real time.
This is a huge quality improvement over typical online Python
interpreters, and with the addition of mypy static type checking
(again, entirely in the browser) this nears even closer to a native
Python installation.
wiki categories
- Constructs a compact Wikipedia category hierarchy.
For another project, I needed a way to navigate the Wikipedia category
hierarchy quickly, and without the Wikipedia API. Originally using the
above wiki_dump project, I constructed a pipeline to
automatically extract category data from the
Wikimedia assets, transform it into a graph
structure, and upload it to GitHub Pages.
There were multiple limitations that needed to be properly handled:
the GH runners have a fairly low space limitation, and a GH Pages
artifact can only be so large. This necessitated using streaming to
process the data as it was being given to the runner without
collecting much memory over the course of the run, and creating a
compact data format
that can be easily parsed.